Method Overview
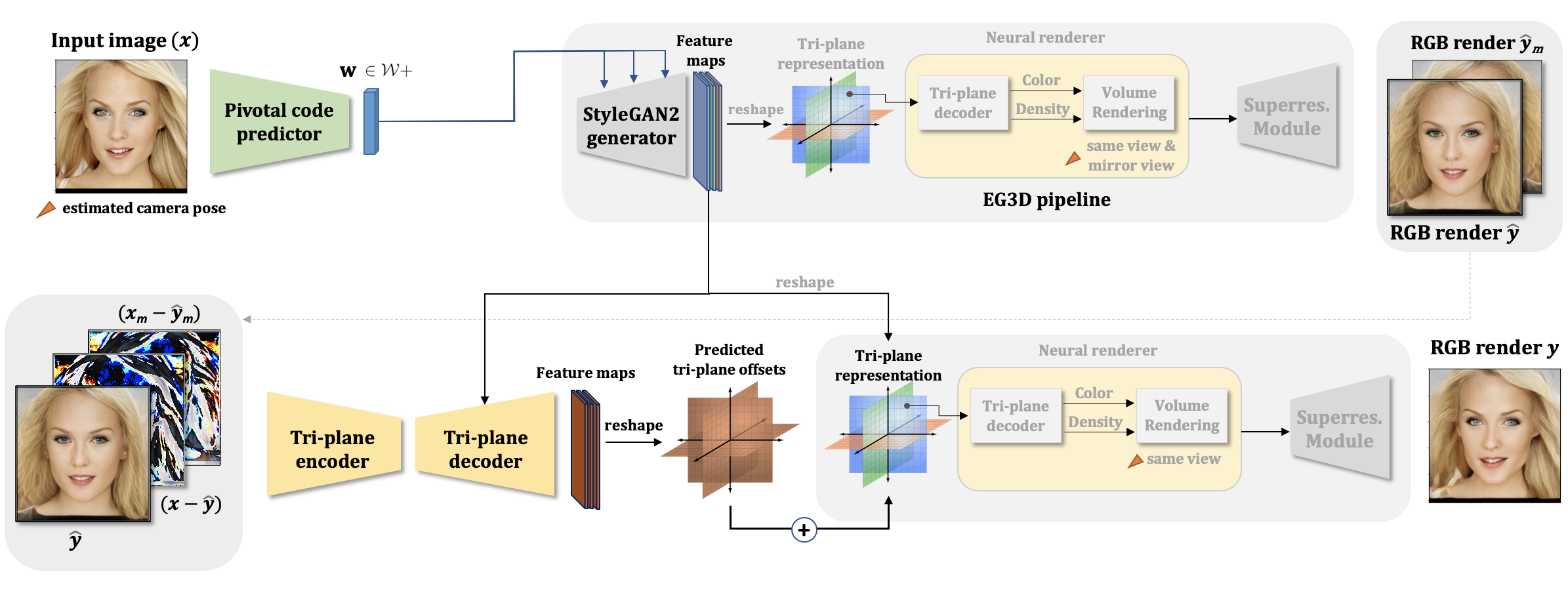
Inversion is performed in two phases.
In the initial phase, given an input image, an encoder is utilized to predict pivotal latent code and obtain initial an input-view RGB image and a mirror-view RGB image.
In the second phase, the initial input-view reconstruction, the difference between the input image and the input-view reconstructed image, the difference between a mirror image and mirror-view reconstructed image, and the first branch tri-planes features are processed by an auto-encoder to estimate tri-plane offsets. The offsets are numerically added to the tri-planes output by the EG3D generator. The final reconstruction is obtained by processing the refined tri-planes by the renderer block.